
大规模短文本去重
背景
最近接到一个需求,需要对300万的短文本进行去重,如果按照传统的方法一一比对,那就是$O(n^2)$复杂度。对于300万的数据来说,这个时间成本是不可接受的,因此需要一个合适的算法提高去重效率。在这里就用到了 MinHash 和 LSH(Locality-Sensitive Hashing),前者是将文本降维转换成哈希,后者是通过索引加快查找过程。
MinHash
传统的 hash 算法将不同长度的字符串转化为相同长度的字符串,对于相似的内容,即使只差了一位,转化后的结果也是截然不同。
MinHash 能够将相似的文本转化成相似的 hash
MinHash 就是将行多次随机打乱,找出第一个非零行的索引序号,作为最小哈希值 $h(i)$
假设我们这里有三个文本(假设a、b、c、d是四个不同的词):
S1 = abcd
S2 = bcd
S3 = ad
我们用一个特征矩阵来表示比较直观一点:
| S1 | S2 | S3 | |
|---|---|---|---|
| a | 1 | 0 | 1 |
| b | 1 | 1 | 0 |
| c | 1 | 1 | 0 |
| d | 1 | 1 | 1 |
可以用如下3步来简单理解如何生成hash:
1)将行随机打乱。
2)行打乱后,针对每个S1、S2、S3看第一个1所在的行号,这个行号就是这个集合的最小哈希值。
3)设定hash的大小,如果是N,则重复上述步骤,随机进行N次行打乱,得到N个最小哈希值,那么这N个最小哈希值组成的集合就是S1、S2、S3对应的哈希签名。
为什么要进行行变换使用第一个1所在的行号作为最小哈希值呢,这样生成的哈希有什么意义呢?
我的理解是,这近似于一种抽样方法,用少数的哈希值来代替原本稀疏的特征矩阵,至于用第一个1所在的行号作为最小哈希的原因在于行号一样的集合原本的特征值都是1,这样得到哈希值也是一样,那么两个相似的文本得到的哈希在很大程度上就具有相似性,即解决了传统的hash算法存在的相似文本得到差别很大的哈希的问题。
我们直接看例子:
基于上述的矩阵,我们进行第一次行变换得到如下新矩阵(行号从0开始算):
| S1 | S2 | S3 | |
|---|---|---|---|
| b | 1 | 1 | 0 |
| c | 1 | 1 | 0 |
| a | 1 | 0 | 1 |
| d | 1 | 1 | 1 |
那么对于S1来说,顺着行号往下走,发现第一个1所在的行号是0,那么h(S1) = 0,依次类推,h(S2) = 0, h(S3) = 2。
局部敏感哈希算法(Locality Sensitive Hashing)
MinHash 只是将文本转换成了 hash 值,并没有减少比较的次数,当数据量大的时候依然很消耗时间,所以在这里就需要用到局部敏感哈希算法(LSH)
LSH是一种基于 MinHash 的加速索引算法,建立一种新的索引
其基于思想:如果将两个向量以相同方法划分若干段,如果这两个向量相似,那么他们被划分出的对应若干段中存在某段完全相同(=段中每维完全相同=hash值相同=被分到同一个hash分桶)的概率也很高;同理不相似的向量,其哈希值只有很小的概率是相同的。那么我们就可以只比较可能相似的样本,不太可能相似的样本就不比较,这样就减小了比较次数
LSH具体地算法是:
1.将每个原向量(一个数据点)通过min-hash得到的hash签名(下称:向量),划分为b段,每段有r行
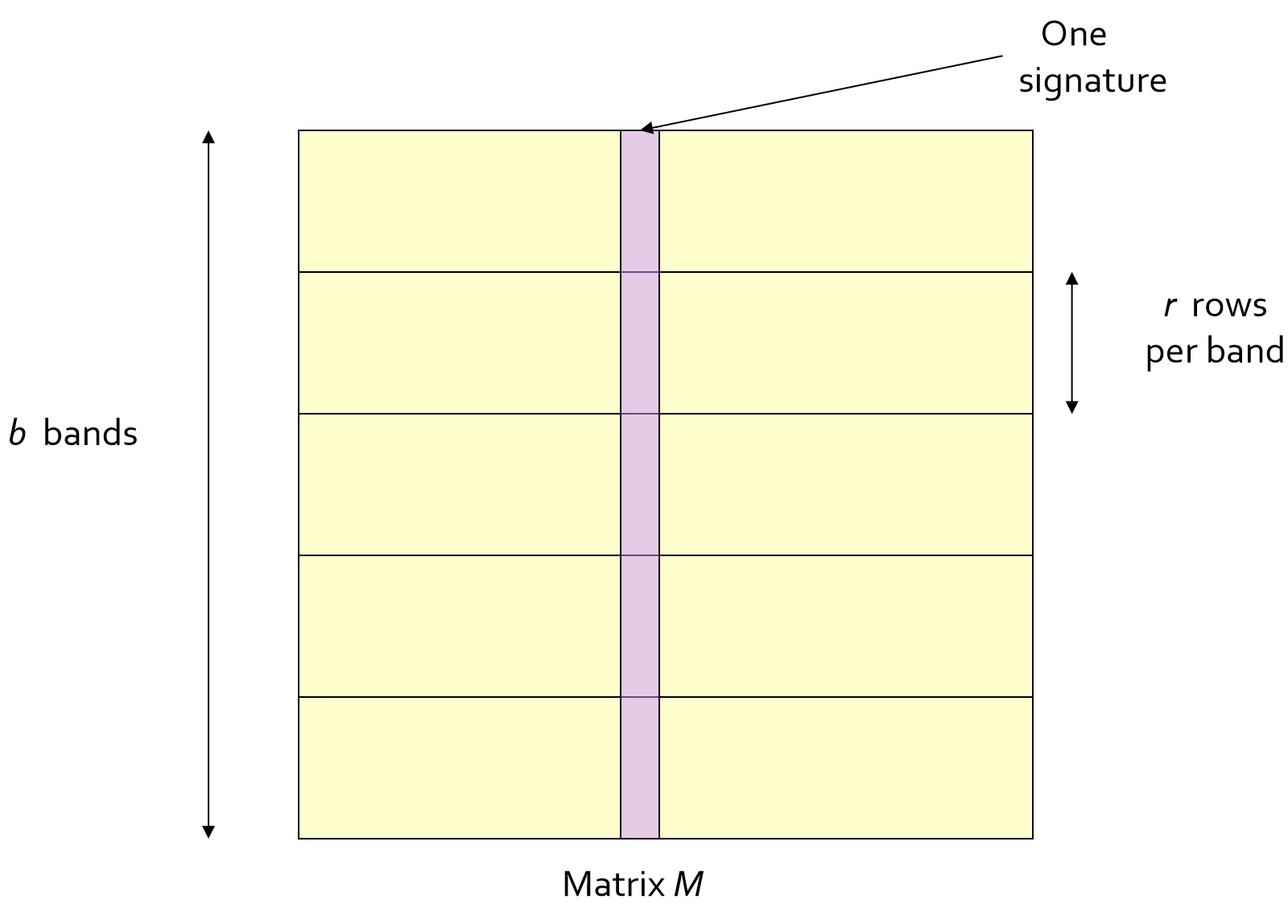
如图矩阵 $M$ ,每一列代表一个向量,每一行就是一个向量的维度,$r$ 个维度(行)组成一个段
2.对每行的每个段进行 hash 映射,不同样本(竖)的该段截取的部分段向量(横)如果相同就会被映射到一个桶中。
(每一行可以使用相同的 hash 函数,但是每一行各段都是被映射到不同的数组的,数组里的每一个元素就是桶)
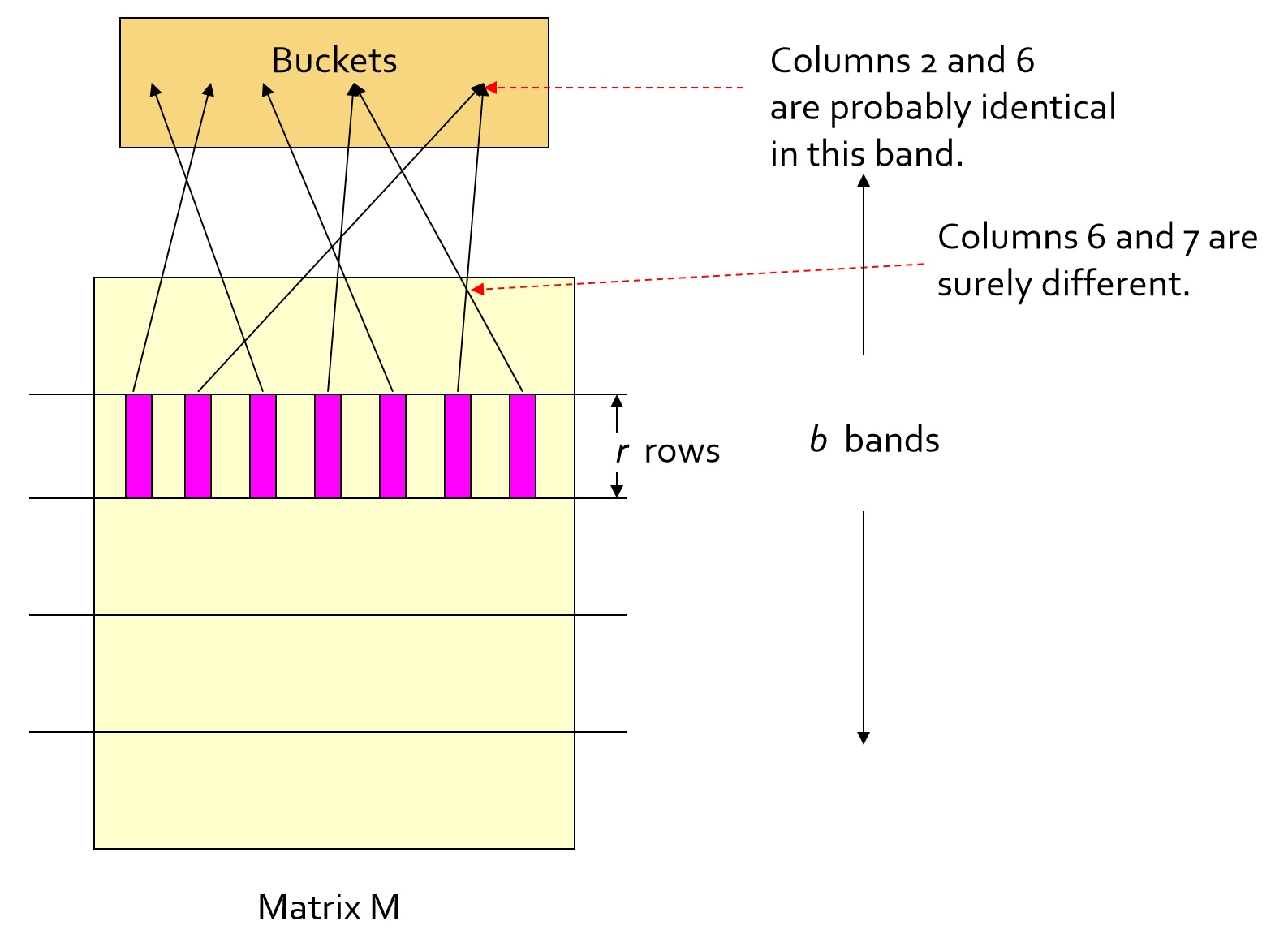
3.我们应用一个假设:我们称每个段的每一个桶内,即不同样本中至少有一个段相同(=hash值相同=被分到同一个hash分桶)的样本为候选相似样本。通过下面的证明可得,我们只对候选相似样本进行比较,便可以以极大概率找到所有可能相似样本。
假设的证明:我们假设 AB 两个样本相似度为a,那么将A、B分成b段,每段r行。那么A、B在某段里,每一行的相似概率就为 $a^r$, 那么A、B在该段每一行都不相似的概率就为 $1−a^r$ ,A、B所有段都不同的概率为$(1−a^r)b$ ,A、B至少有一个段相似的概率为 $1−(1−a^r)b$ ,最后这个式子就是两个样本可能相似的概率
理解名字:“局部敏感哈希”,这个局部就是指的这个分段。如果两个向量局部相同,根据上面证明,那么两个向量可能相似的概率就远远大于不可能相似的概率。
其它
性能测试
测试机器:MacBook Pro (15-inch, 2016)
MinHash 生成性能
测试数据:300万条数据
耗时:30分钟
LSH 建立索引
测试数据:300万条数据
耗时:5分钟
LSH 查询性能:
测试数据:300万条数据
耗时:5分钟
提示:
在生成 hash 的过程中,文本长度会对性能有着明显的影响,如果准确度要求不是很高,可以截取固定长度的文本。